
Can we learn to ignore objects in our visual field?
When we look through our visual environment, we often get distracted. Can we learn to overcome this distraction and if yes how does it work?
In our everyday life, we search all the time. We spend a lot of time searching for our keys, our reading glasses or a subway stop. Visual searches are the most prominent task our visual system has to cope with (Wolfe, 1998). Imagine searching for the book you are currently reading. If the book happens to lay on your bed, the search is quite easy: it pops out from its environment. But if the book is in a big bookshelf among many other books, the search is comparably hard. In the 1980’s, Anne Treisman in fact suggested, that there are two different kinds of searches: parallel searches and serial searches. In parallel searches, the search target pops out from the environment so that you are always able to find it instantly, regardless of how many distracting objects (in the example, other books) are to be found in the scene. In contrast, if the search target does not pop out, as is the case in serial searches, you have to individually scan each object in the scene to know whether it is your target object or not. In this case, the more distracting objects comprise the scene, the harder the search is. In both parallel and feature searches, the first initial search is characterised by the attributes of the search target. In our example, it depends on the color and artwork of the book, the title and the author. However, subsequent searches are additionally driven by its location in space. If you remember that you put your book in the top shelf, this information can guide your efforts to this region and thereby make search more efficient.
This prioritising of certain regions of the search space is accomplished by a process called location probability cueing. It means that location probability guides your search: regions where the book is more likely to be, are prioritised, while regions where the book is less likely to appear are ignored. This mechanism also works for ignoring prominent distracting objects. Imagine that in your bookshelf, your target book pops out from the rest of the books by being the only one that is tilted (i.e. the only one leaning against another book, all other books are standing straight up). Further, there is one book that is quite distracting because it is the only red book, while all other books, including your target book, are blue. We tried to model a similar situation in laboratory studies. In those studies, you have to do an artificial version of this ‘book search’ about 800 times (to gain some perspective, this takes about 20 minutes in total). The study participant has to look for a slightly tilted gray bar among vertical gray bars and respond as fast as possible. Sometimes, one of those other bars is not gray but red and thereby highly distracting.: it captures your attention because it looks so different from the rest. The distracting bar appears almost always in the upper half of the visual scene (but the participant does not know this). In these laboratory studies, we were able to show that when the distracting object appears in the region where it appears often, reaction times are much faster, compared to when it appears in the region where it appears seldomly.
Location Probability Cueing: An Applied Version
 However, as I mentioned earlier, our laboratory studies look quite artificial and nothing like an everyday task, so I wanted to create a
However, as I mentioned earlier, our laboratory studies look quite artificial and nothing like an everyday task, so I wanted to create a
version that looks slightly more realistic and see whether I can find the same effects again. Using Photoshop, I created 200 different bookshelves, like the one on the right. The task was to find the book that was slightly tilted to the right and say whether the “+” is at the top of the book (press ‘x’) or at the bottom of the book (press ‘m’). If you want to see how it feels in practice, check out the online experiment here. The experiment takes about 5-7 minutes. In half of the bookshelves, there is a uniquely distracting red book. Overall, it appears 45% on the top shelf and 5% on the bottom shelf (for half of the participants, this is flipped) and it is not present in 50% of the bookshelves.
Using this online implementation, I recruited 103 participants from Reddit’s /r/SampleSize (thanks, guys!) and Clickworker. I wanted to analyse the following:
- How fast are people responding overall? In comparable laboratory studies, reaction times are usually at around 600-800ms.
- Are they responding faster when there is no distracting red book in the display?
- Are they responding faster when the distracting red book appears in the more likely region?
Results
Response time overall: Overall, people responded in 894ms on average (median). This is slightly slower than typical laboratory studies but to be expected, because in labs, we typically have young students who are quite motivated and usually trained in similar tasks. In unrestricted online studies the average age might be higher and the background of the participants is much more diverse. In my view, this makes it more interesting. To be noted, for this first online study, I did not assess any demographical information, in order to not discourage anyone from participating because of privacy concerns.
Is the red 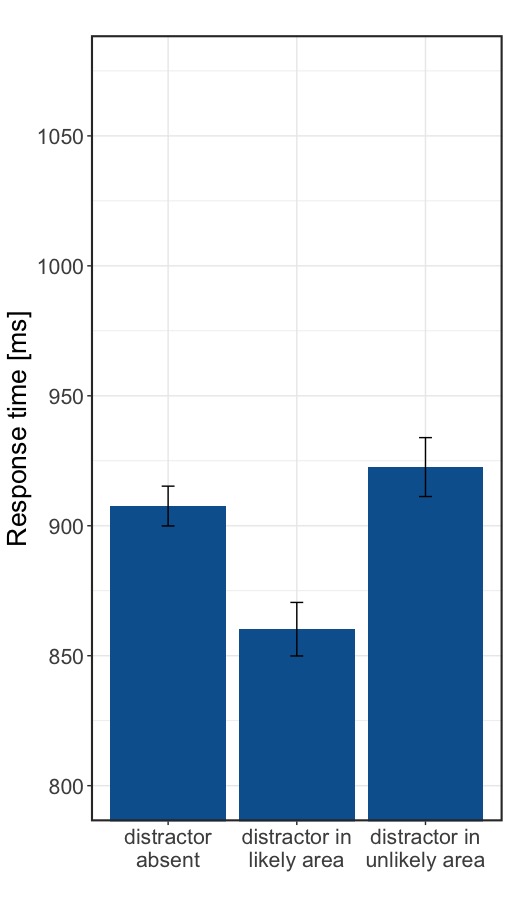 distracting book actually distracting? To investigate this, I average, for each participant, the trials in which a distractor was present and those in which it was absent and create a grand average over all participants. This results in a mean response time of 908ms when the distractor is not there and a response time of 881ms when the red book distractor is there. This is surprising! The red book does not distract but seems to be even slightly helpful! To make this observation statistically sound, we compare the two groups of trials (distractor present vs. distractor absent) with a paired t-test. There is a significant difference of 26ms, t(75) = -3.85, p < .001, dz = 0.44, 95% HPD [-38.23 ms, -11.33 ms], BF10 = 89. This means, that we can actually show that the red book helps participants to respond faster.
distracting book actually distracting? To investigate this, I average, for each participant, the trials in which a distractor was present and those in which it was absent and create a grand average over all participants. This results in a mean response time of 908ms when the distractor is not there and a response time of 881ms when the red book distractor is there. This is surprising! The red book does not distract but seems to be even slightly helpful! To make this observation statistically sound, we compare the two groups of trials (distractor present vs. distractor absent) with a paired t-test. There is a significant difference of 26ms, t(75) = -3.85, p < .001, dz = 0.44, 95% HPD [-38.23 ms, -11.33 ms], BF10 = 89. This means, that we can actually show that the red book helps participants to respond faster.
What about the different regions? Remember that the red book appears 45% of the time in the upper shelf and 5% of the time in the bottom shelf. Is there a difference in how the red book is helpful? When we look at the results in the plot on the left, we can see that only when the red book appears, where it appears more often, response times are faster. Again, we can compare this difference between the likely area and the unlikely area by means of a paired t-test and find a difference of 62 ms, t(75) = -3.77, p < .001, dz = 0.44, 95% HPD [-93.49 ms, -29.43 ms], BF10 = 138.
A lot can be analyzed in addition to what I showed here (and in typical laboratory studies, we analyze a lot more) but instead of chewing all the analyses out here, I invite everyone to jsut play around yourselves. You can find the raw data and my analysis script (written in R) below.
What To Take From This
So this means that there is a big difference in how the red distracting book is perceived or attended to just based on where it appears more likely. When you expect it at a certain shelf, it seems to guide your search faster towards the tilted target book. But do these small differences actually matter in practice? Yes they do! Just consider the last final of the IAAF World Championship Men’s 100m sprint. A difference of 62ms, or 0.062s would almost mean the difference between 1st place and 4th place!
Additional Analyses
Before I conducted the main analyses reported above, I had to exclude 27 participants, because they had a very low accuracy, indicating that they didn’t understand the task correctly. I then excluded all repetitions (trials), in which participants did an error as those are usually harder to interpret (it was 1.4% of all trials).
Download
All bookshelves, pre-proccessed data and analysis script can be downloaded here (25MB).
If you have any questions or concerns, feel free to leave a comment or contact me directly.

